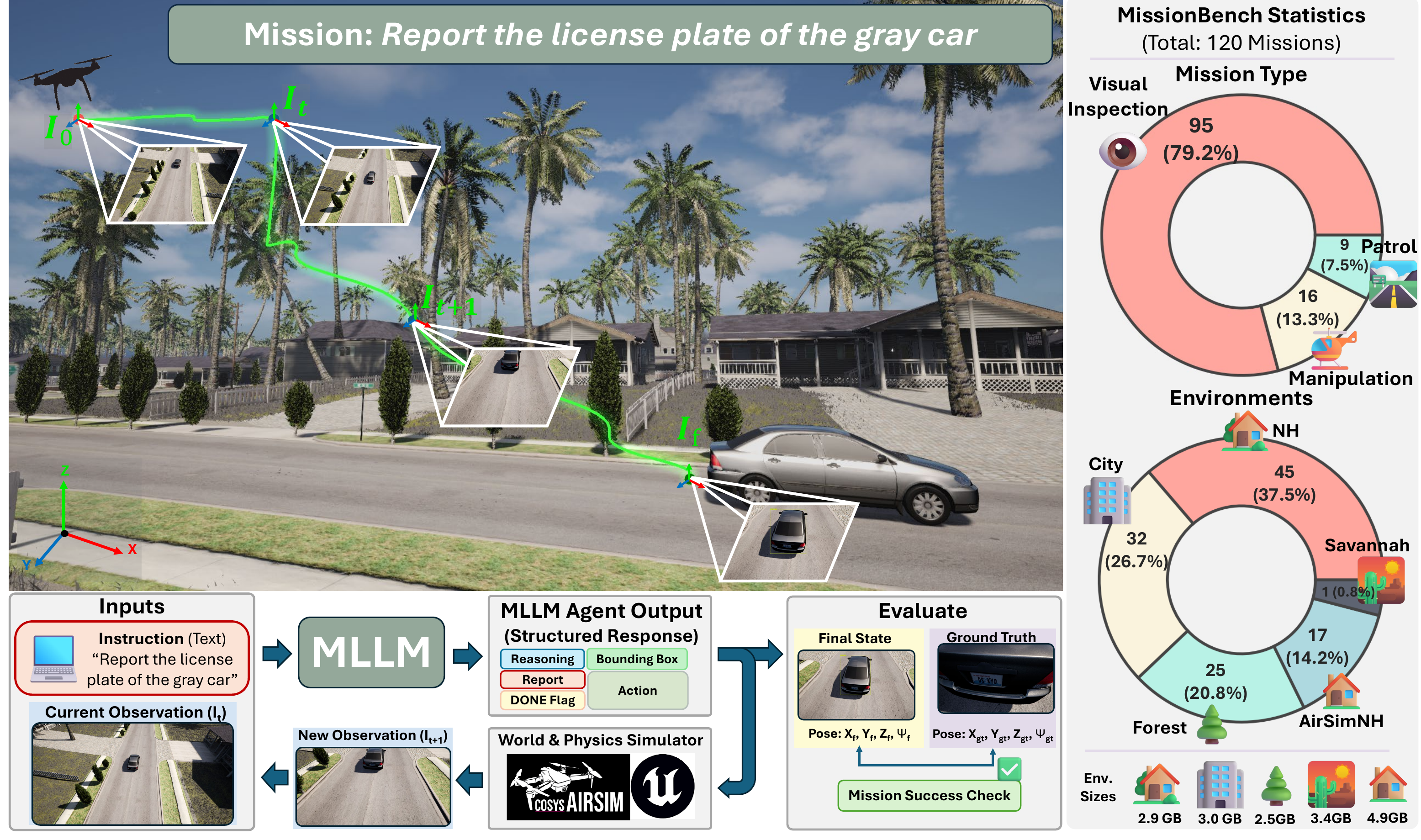
MissionBench is a mission-level aerial benchmark for testing frozen, off-the-shelf MLLMs on
long-horizon drone tasks from a single high-level instruction. Instead of evaluating isolated
skills, it measures end-to-end performance in realistic environments where agents must coordinate
perception, planning, movement, viewpoint selection, and reporting. Across 22 models evaluated
in the paper, even the best systems achieve below 35% success, showing that mission-level
embodied reasoning remains a hard open problem.
- 120 missions across 5 photorealistic environments.
- 4 task families: Reporting, Inspection, Manipulation, and Patrol.
- A closed-loop evaluation protocol that separates mission understanding from spatial
execution.
- Evaluation of 22 open- and closed-source MLLMs in zero-shot settings.
Current models struggle with robust mission completion in aerial environments. Performance
improves with model scale, but gains are still far from reliable autonomy. Strong mission
performance requires coordinated capabilities beyond visual recognition alone.