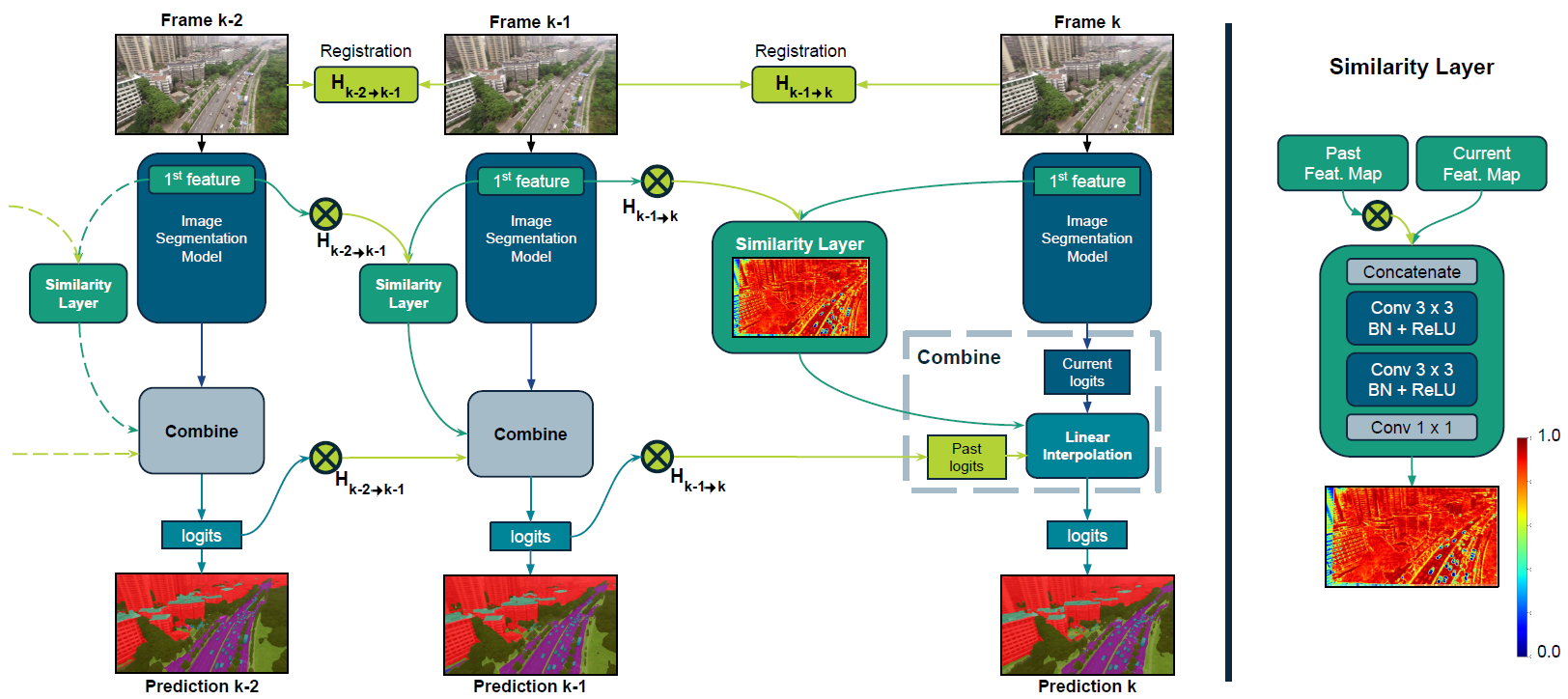
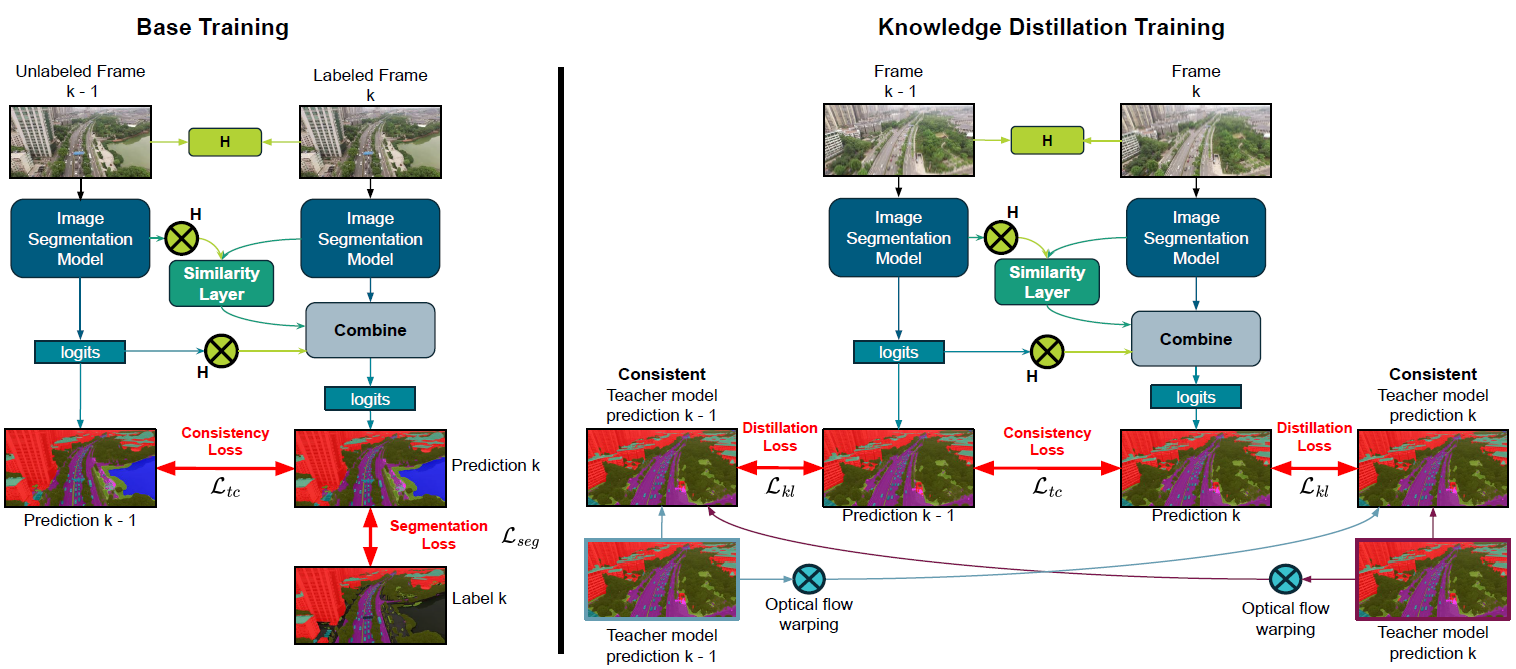
SSP Overview
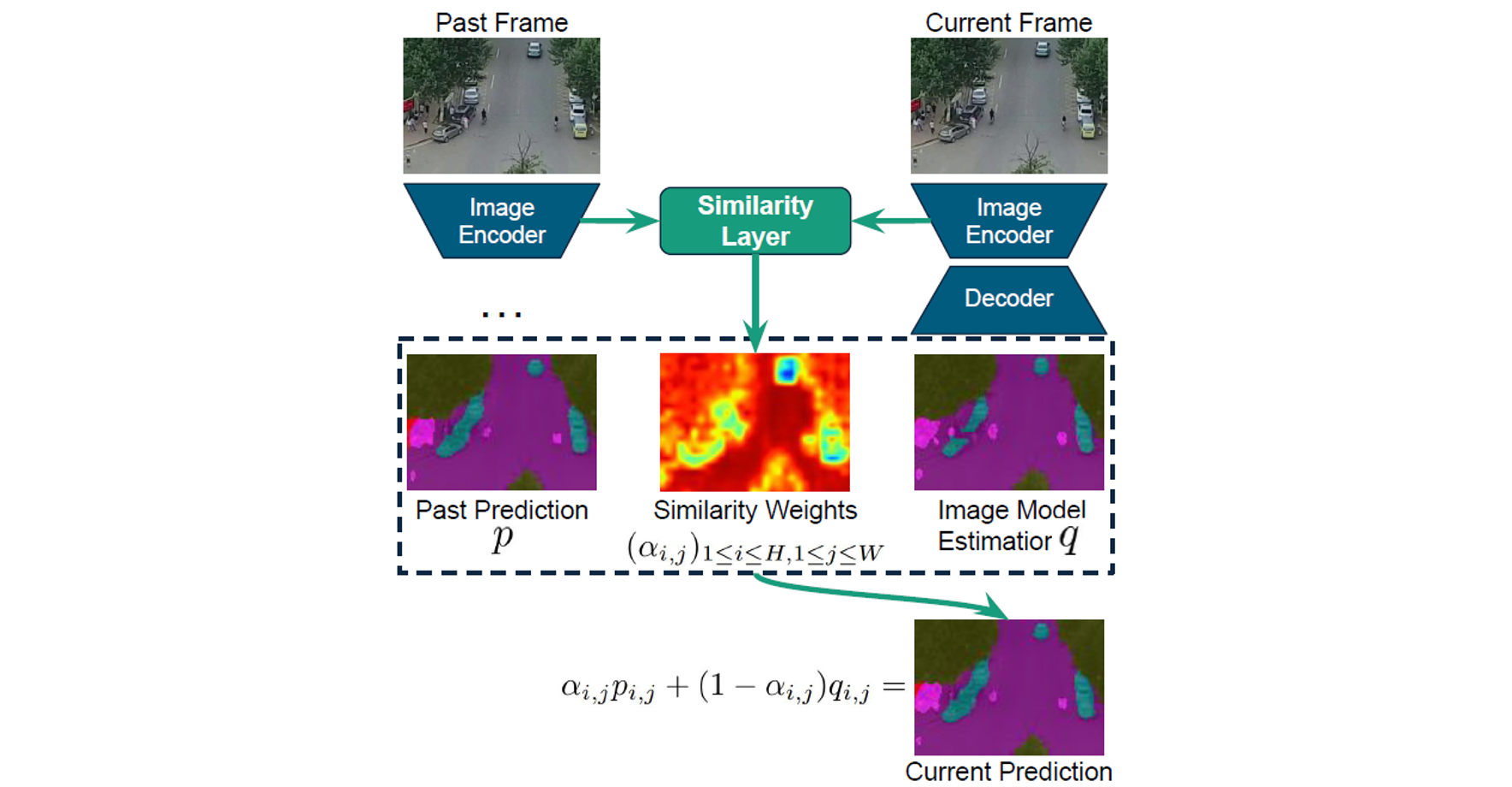
SSP enhances temporal consistency by combining current segmentation predictions with past frame predictions using linear interpolation. The interpolation weights, determined by semantic feature similarities between consecutive frames, are computed through convolutional layers. Additionally, global registration alignment compensates efficiently for camera movements, aligning previous predictions to the current frame without relying on expensive optical flow.